
Are your humans reviewing the cases that need them, or rubber-stamping the ones AI already got right?
Designing Human in the Loop
Most failed AI projects fall on one of two sides of a false binary. Either everything has to go through a human, in which case the AI saves nobody any time and the project gets quietly written off as "didn't deliver ROI." Or nothing goes through a human, the AI makes a confident error in front of a customer, and the screenshots become someone else's content.
The right answer is almost always somewhere in between. The question is where, exactly, and the answer is more specific than most teams think.
This piece is about designing the human in the loop properly. Where humans should stay involved, where they shouldn't, what value they're actually adding, and how AI earns the autonomy to run unsupervised over time.
Key Takeaways
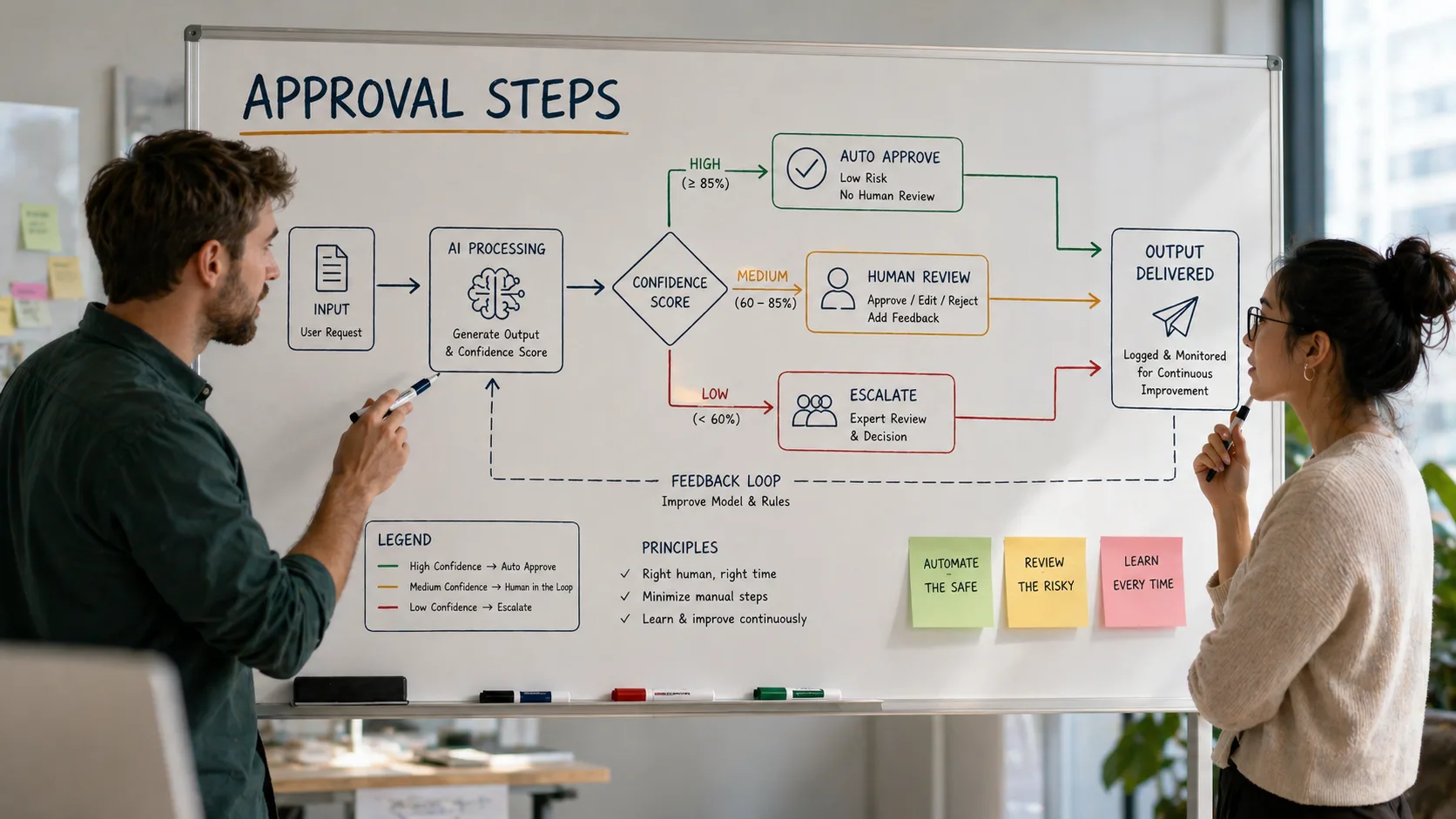
- Two failure modes: humans on everything (no ROI) or humans on nothing (public incidents). The middle ground is the design.
- Humans add real value in three places: judgement, accountability, and recovery. Rubber-stamping is not on the list.
- AI earns autonomy on a gradient over months, not in one decision. Confidence on one kind of case doesn't transfer to another.
- A review point that takes twelve clicks gets skipped. A one-click review with context on screen actually happens.
- Walk the workflow step by step and ask three questions per step: cost of error, judgement vs rules, accountability. The answers tell you where humans belong.
The false binary
Pilots tend to start with humans involved everywhere. Every output gets reviewed. Every action gets approved. Every email gets read before it goes. That's appropriate at the pilot stage. It's how you build trust in the system, find the cases it gets wrong, and decide what's safe to let it do.
What goes wrong is what happens next.
Some projects never come out of that mode. The human review stays on every output forever, the team never gets the time back, and the AI starts to feel like an expensive way to make people read more of their own work. ROI never lands. The project quietly winds down.
Other projects swing the opposite way. The team is impressed with the early pilot results, decides the AI is "ready," and rips out all the human review at once. The AI runs autonomously, mostly works, occasionally produces something that looks fine but isn't, and that one bad output costs more than all the saved time was worth.
Both outcomes are predictable. Both are avoidable. The thing that prevents them is treating "where do humans belong in this workflow" as a design question rather than a default.
Where humans actually add value
The first move is being honest about what humans are doing in an AI workflow. Most of the time, it's one of three things.
Judgement on the cases AI can't handle well. The system flags a case that doesn't match the patterns it was trained for. A human makes the call. The value is genuine. The human is doing the part of the work the AI shouldn't be doing.
Accountability for decisions that need a name on them. A contract, a price quote, a clinical recommendation, a hiring decision, a customer concession that breaks the rules. The AI can draft, suggest, even recommend. The decision belongs to a person because someone has to own the outcome. The value is the accountability itself, not the reading.
Recovery when something has gone wrong. A customer complaint that's escalating. An output that produced an unexpected downstream effect. A pattern in the data that suggests the system is drifting. Humans here are catching what the system can't catch about itself.
These are the places human in the loop is genuinely valuable. Notice what's not on the list: humans rubber-stamping outputs the AI would have got right anyway. That's not value. That's busywork dressed up as oversight.
The most common design mistake we see is putting humans on the rubber-stamp work and leaving the actual judgement, accountability, and recovery work to chance.
Earning autonomy over time
A pilot starts with humans involved everywhere because nobody has evidence yet that the AI works. As evidence builds, humans should move out of the places they aren't adding value, and stay in the places they are.
This is what "earning autonomy" looks like in practice. Not a binary switch. A gradient that moves slowly as the system proves itself.
Week one. AI drafts every output, human reviews every output, every decision goes through a person. You're learning the failure modes.
Month two. The AI is reliable on the obvious cases. Human review moves to a sample, plus everything the AI flags as uncertain. The team learns where the system is genuinely good and where the edges are.
Month six. AI runs autonomously on the well-understood cases, drafts on the medium ones for fast human approval, escalates the genuinely difficult cases. The team has clear data on the failure rate at each tier and can make informed decisions about what to loosen further.
Year one. The system has earned trust on a defined scope of work. New scope starts back at week one, because confidence on one kind of case doesn't automatically transfer to another.
The mistake we see most often is collapsing this gradient into a single decision made too early. "The pilot worked, so let's automate everything." That's how AI projects become public incidents.
The review that doesn't happen
Even when teams design human review correctly, it often quietly stops happening.
The reason is almost always design. The review is too slow, takes too many clicks, sits in a tool nobody opens, requires context the reviewer doesn't have. Within a few weeks, the review starts getting skipped. Within a few months, it's been silently dropped. Quality drifts and nobody notices until something visible breaks.
If a human in the loop point exists, the design needs to make it actually happen.
That means making the review fast. One click to approve, one click to reject, with the relevant context already on screen. It means making it part of someone's actual workflow, not a separate task they have to remember. It means making sample review automatic, not opt-in. It means tracking whether the review is happening at the rate it's supposed to and flagging when it isn't.
A review point that takes twelve clicks to complete will be skipped. A review point that takes one will be done. That sounds like a small detail. It is the difference between a workflow with real human oversight and one with theatre.
A practical way to design it
For any AI workflow you're building or running, the design exercise we use is straightforward.
Walk through the workflow step by step. For each step, ask three questions.
Is the cost of an error at this step low or high? Low-cost errors can be caught downstream or simply absorbed. High-cost errors propagate and damage things you can't easily undo.
Does this step need genuine judgement, or can it be done well by following clear rules? Rule-based work is AI-shaped. Judgement work needs a human, or at minimum, human approval before the action.
Does this step need accountability? Is there an outcome here that someone needs to put their name to? If yes, a human signs off, even if the AI did all the work.
The answers tell you where humans belong. High-cost errors plus genuine judgement plus accountability is where humans stay involved. Low-cost errors with rule-based work is where the AI runs on its own. The middle, judgement with low cost, or rules with high cost, is where the AI drafts and a human approves.
Write it down. Not in a head-of-someone's-mind way. Document which decisions the AI handles end to end, which it drafts for human approval, and which it stays out of entirely. The document becomes the contract for how the workflow actually runs, and the place you go back to when something needs to change.
A note on what this isn't
Human in the loop done well isn't about caution. It's about precision.
The teams who build the best AI workflows aren't the ones with the most human review. They're the ones who put humans in exactly the right places and pulled them out of everywhere else. They get the speed and scale of automation where it works, and the judgement and accountability of humans where it matters. Both at once.
The teams who get it wrong are the ones who treated this as binary. Either too cautious to get value, or too autonomous to keep trust. The middle ground isn't a compromise. It's the design.

Doriel Alie
Doriel is the founder of Operational AI Systems, an AI consultancy and software development agency in Milton Keynes. More about Doriel.
Trending
Related post
Expand your knowledge with these hand-picked posts.

AI Trade-offs Nobody Warns You About
What manual processes catch that nobody writes down, what AI removes, and how to design those checks back in before quality slips. The honest audit before you automate.

AI Architecture That Reaches Production
Sync vs async, queues, retry logic, state handling, and the architectural choices that decide whether your AI scales or collapses under real load.
System Status
