
Why does the AI pilot that wowed the board quietly die three months in?
AI Workflows That Survive Production
Most AI pilots look like miracles in the demo and like dead weight three months later. The team that built it has moved on. The handful of people who knew how it worked are stretched thin. The model occasionally produces something baffling and nobody is clear on what to do about it. Usage tails off. Quietly, the project gets shelved.
This isn't a model problem. It's a workflow design problem. Pilots are built to impress. Production AI workflows are built to survive. They are different jobs and they need to be designed differently from day one.
If you're commissioning, building, or sponsoring AI inside a business, this is the gap to close before you ship anything.
Key Takeaways
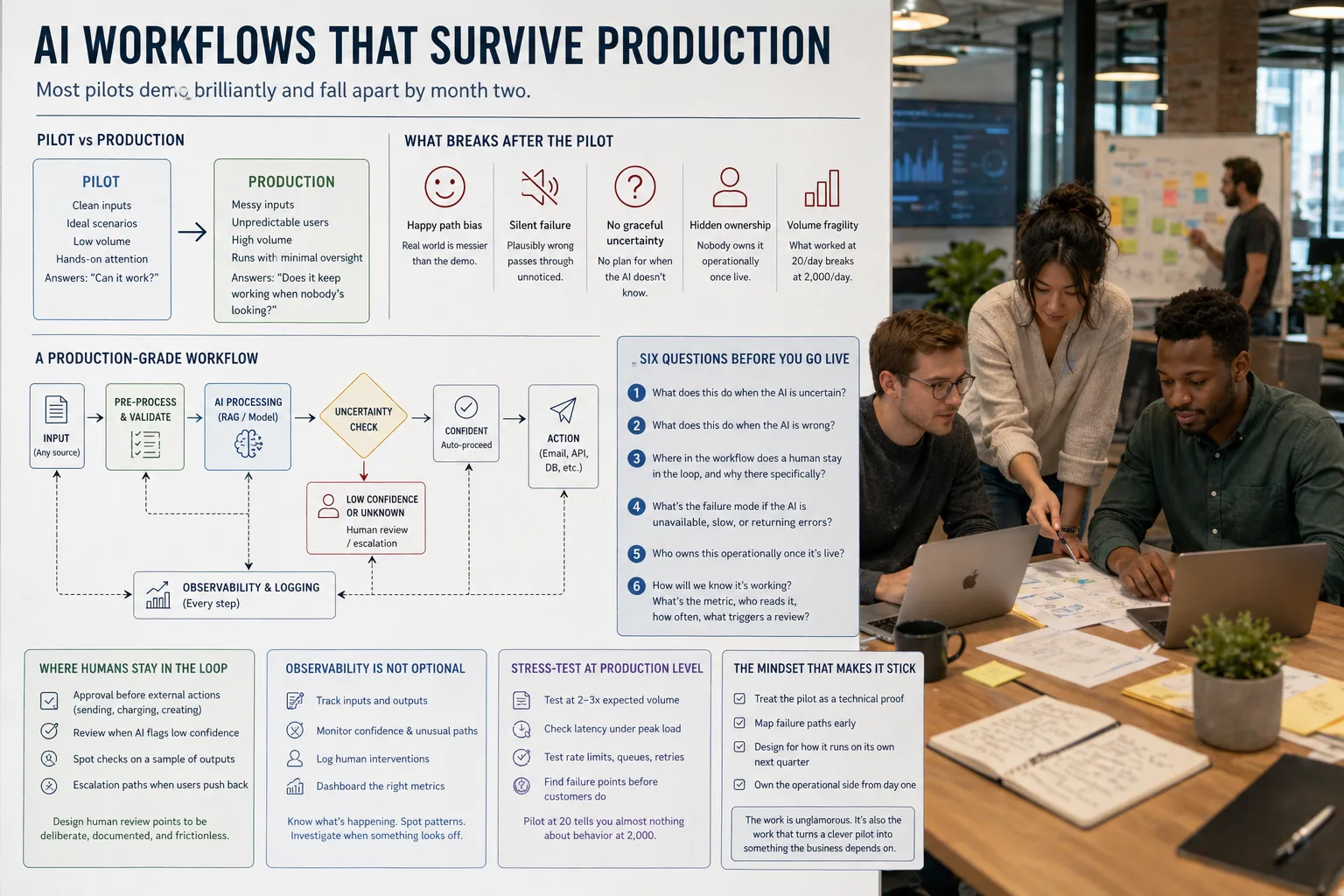
- Pilots answer "can it work?" Production has to answer "does it keep working when nobody is looking?" Different jobs, different designs.
- Five things kill pilots in production: happy path bias, silent failure, no graceful uncertainty, hidden ownership, and volume fragility.
- Before going live, the team should be able to answer six questions without hesitation about uncertainty, error handling, human review, failure modes, ownership, and metrics.
- Human-in-the-loop is not everywhere or nowhere. It belongs at specific, deliberate, frictionless points such as approvals, low-confidence flags, and escalations.
- Observability and stress-testing at two to three times expected volume are not optional. They are the unglamorous work that turns a clever pilot into something the business can actually depend on.
Why pilots and production are different jobs
A pilot exists to answer one question: can this AI do this task at all? You point it at clean inputs, ideal scenarios, a co-operative user, and you watch the output. If it works, the demo lands and the project gets green-lit.
Production is a different game entirely. The inputs are not clean. The scenarios are not ideal. Users do unpredictable things. The AI is uncertain on edge cases nobody anticipated. Volume is ten or fifty times what the pilot tested. And nobody is watching it, hour by hour, the way the pilot team did.
The pilot answers "can it work?" Production has to answer "does it keep working when nobody's looking?"
Most failed AI projects tried to scale a pilot answer into a production environment. The two questions need different designs.
What actually breaks after the pilot
A few specific things kill AI workflows once they go live.
The first is happy path bias. Pilots showcase the cases where the AI sails through. Real usage includes the messy ones, the ambiguous ones, the inputs that don't match anything the AI saw in testing. If the pilot did not include those, the production version will choke on them.
The second is silent failure. The AI produces something wrong, but plausibly wrong. Nobody flags it because nothing looked broken. By the time someone notices, fifty downstream actions have already happened.
The third is no graceful uncertainty. When the AI doesn't know, what does it do? Make something up? Refuse? Escalate? If the workflow doesn't have a defined answer, the answer it gives in production will be whatever the model felt like that day.
The fourth is hidden ownership. The pilot was someone's project. Production has to be someone's job. If nobody is operationally accountable, drift sets in fast.
The fifth is volume fragility. The pilot ran fine on twenty queries a day. The production version needs to run on two thousand. Throughput, queueing, retry logic, none of it was designed for that load.
The shift in design thinking
Designing AI workflows that survive past the pilot needs a different mindset from designing AI that wins a demo.
A demo-grade workflow asks: does the model produce the right output for this clean input? A production-grade workflow asks: what does this do when the input is wrong, when the model is uncertain, when the user does something we didn't expect, when the upstream system fails, when load triples for a week?
The work of production design is mostly the work of mapping those scenarios, deciding what the system should do in each, and building the handling for it. Unglamorous. Also where pilots succeed or fail.
Six questions to answer before going live
Before any AI workflow moves from pilot to production, the team should be able to answer these without hesitation.
What does this do when the AI is uncertain? Not "the model has a confidence score." What is the actual workflow behaviour? Pause for human review? Default to a fallback answer? Push to a queue for someone to handle?
What does this do when the AI is wrong? How does anyone know? Is there a mechanism for catching it, flagging it, correcting it? Or does the wrong answer sail through to the next step?
Where in the workflow does a human stay in the loop, and why there specifically? Not everywhere. That kills the value. Not nowhere. That kills the trust. Specifically where, and specifically why.
What's the failure mode if the AI is unavailable, slow, or returning errors? Does the workflow stop, queue, retry, fall back to manual? Is anyone alerted?
Who owns this operationally once it's live? Not who built it. Who runs it day to day, responds when it misbehaves, watches the metrics, makes the call when something needs changing.
How will we know it's working? What's the metric, who reads it, how often, what triggers a review?
If the team can answer all six confidently, the workflow is close to ready. If they can't answer most of them, what they have is a pilot, not a production system.
Where humans stay in the loop
This is one of the most common places pilots quietly degrade in production. The pilot had eyeballs on every output, because that's how pilots run. The production version takes the eyeballs off and quality drifts.
The right answer isn't to keep humans on every step forever, because that defeats the point. The right answer is to design human review into the specific places where it adds value and pull it out of the places where it doesn't.
Common shapes that work:
- Human approval before any external action (sending an email, charging a card, creating a contract)
- Human review when the AI flags low confidence
- Human spot checks on a sample of outputs, regardless of confidence
- Human escalation paths when users push back
The rest can run autonomously. That is what scale looks like. The trick is to make the human review points deliberate, documented, and frictionless. If reviewing a flagged output takes someone twelve clicks, the review will quietly stop happening and the workflow will silently get worse.
Observability is not optional
A production AI workflow needs to be visible. Not in a vague "we have logs somewhere" sense. In a "we know what's happening, we can spot patterns, we can investigate when something looks off" sense.
That means tracking what comes in, what the AI did with it, where confidence dropped, where humans intervened, where the workflow took an unusual path. Without that, you have a black box that mostly works, until it doesn't, and then you have no idea why.
This is the bit most pilots skip because it doesn't win demos. It is also the bit that decides whether your team can actually run this thing in six months without it becoming a maintenance nightmare.
Stress-test at the level you'll actually run
A pilot at twenty calls a day tells you almost nothing about behaviour at two thousand. Latency creeps in. Rate limits get hit. Queues back up. The model that responded in two seconds in testing takes fifteen seconds at peak. Errors that happened once in a hundred runs happen ten times an hour.
Load test at two to three times the volume you actually expect, not the volume you expect. Then go and find the failure points before your customers do.
The mindset that makes the difference
The teams that get AI workflows past the pilot treat the pilot as a technical proof, not a finished product. The moment the demo lands, they ask what it would take for this to run on its own next quarter, and they put the answer in scope before anyone celebrates.
The teams that don't, ship the pilot, watch it sag, and conclude AI doesn't work for their use case. Usually it could have. The workflow around it just wasn't designed for the job it was being asked to do.
If you're moving an AI project toward production right now, the most useful thing you can do is map the failure paths, name the human review points, decide who owns it operationally, and stress-test it well above expected load. The work is unglamorous. It's also the work that turns a clever pilot into something the business actually depends on.

Doriel Alie
Doriel is the founder of Operational AI Systems, an AI consultancy and software development agency in Milton Keynes. More about Doriel.
Trending
Related post
Expand your knowledge with these hand-picked posts.

AI Trade-offs Nobody Warns You About
What manual processes catch that nobody writes down, what AI removes, and how to design those checks back in before quality slips. The honest audit before you automate.

AI Architecture That Reaches Production
Sync vs async, queues, retry logic, state handling, and the architectural choices that decide whether your AI scales or collapses under real load.
System Status
