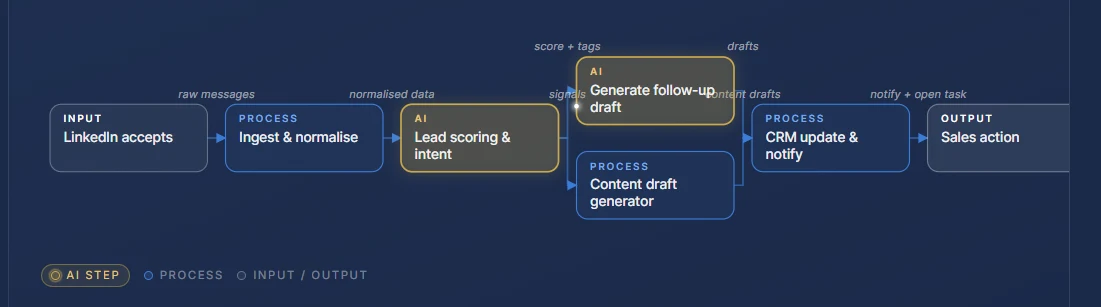
Codebase Explorer
Static diagrams go stale the moment the code changes. PNGs in a docs folder are out of date by the next ticket. We built a local Flask dashboard that parses a multi-hundred-file C# LLM service at request time and renders interactive views: data sources, processes, RAG pipeline, insights pipeline, env configs across five environments, and a Test-vs-Production branch diff. No build step, no database, no cache invalidation. Pull the repo, refresh the browser, see the current state of the system.
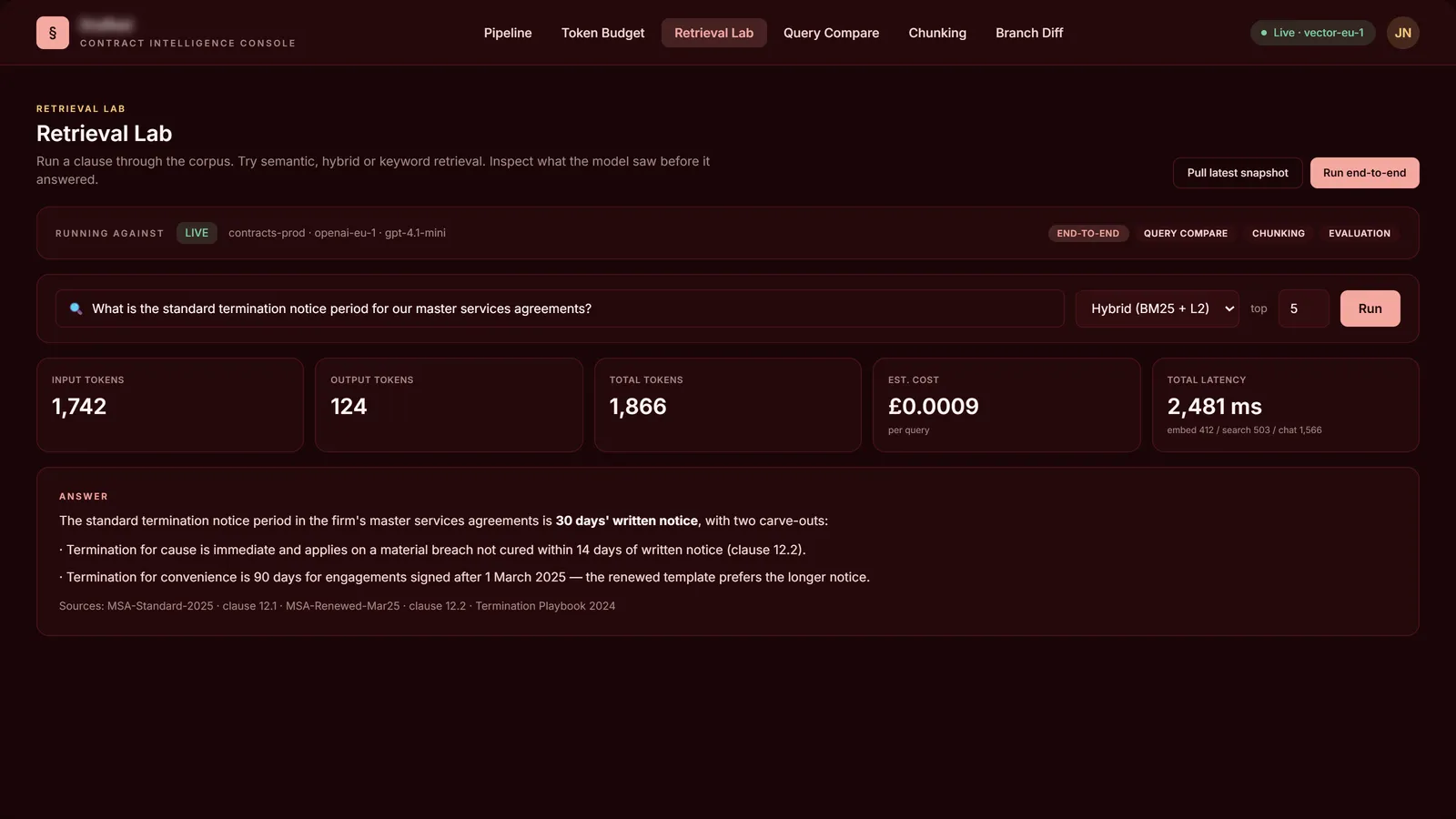
Retrieval Lab · end-to-end query against the corpus
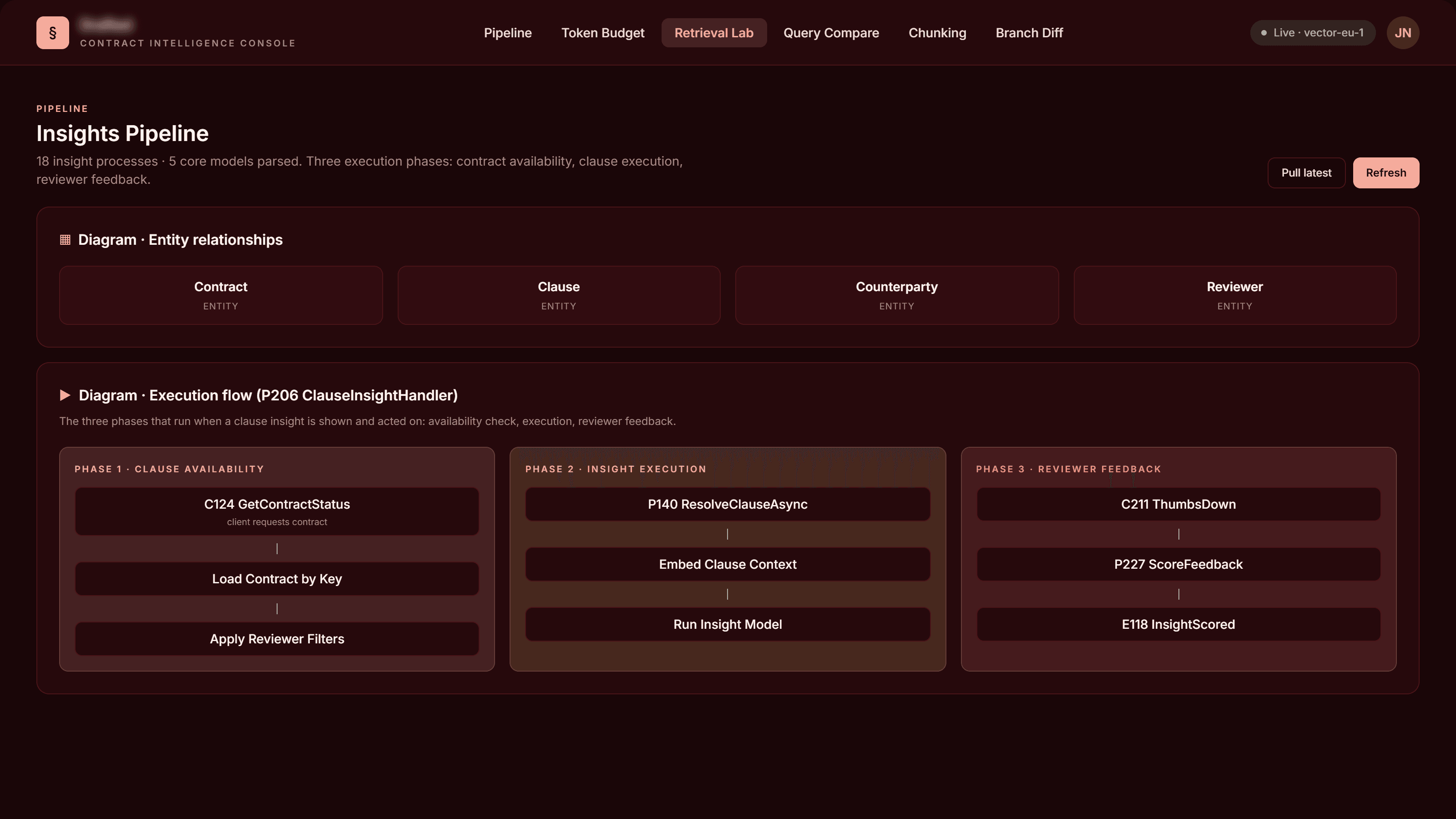
Insights Pipeline · entity ER + three-phase execution flow
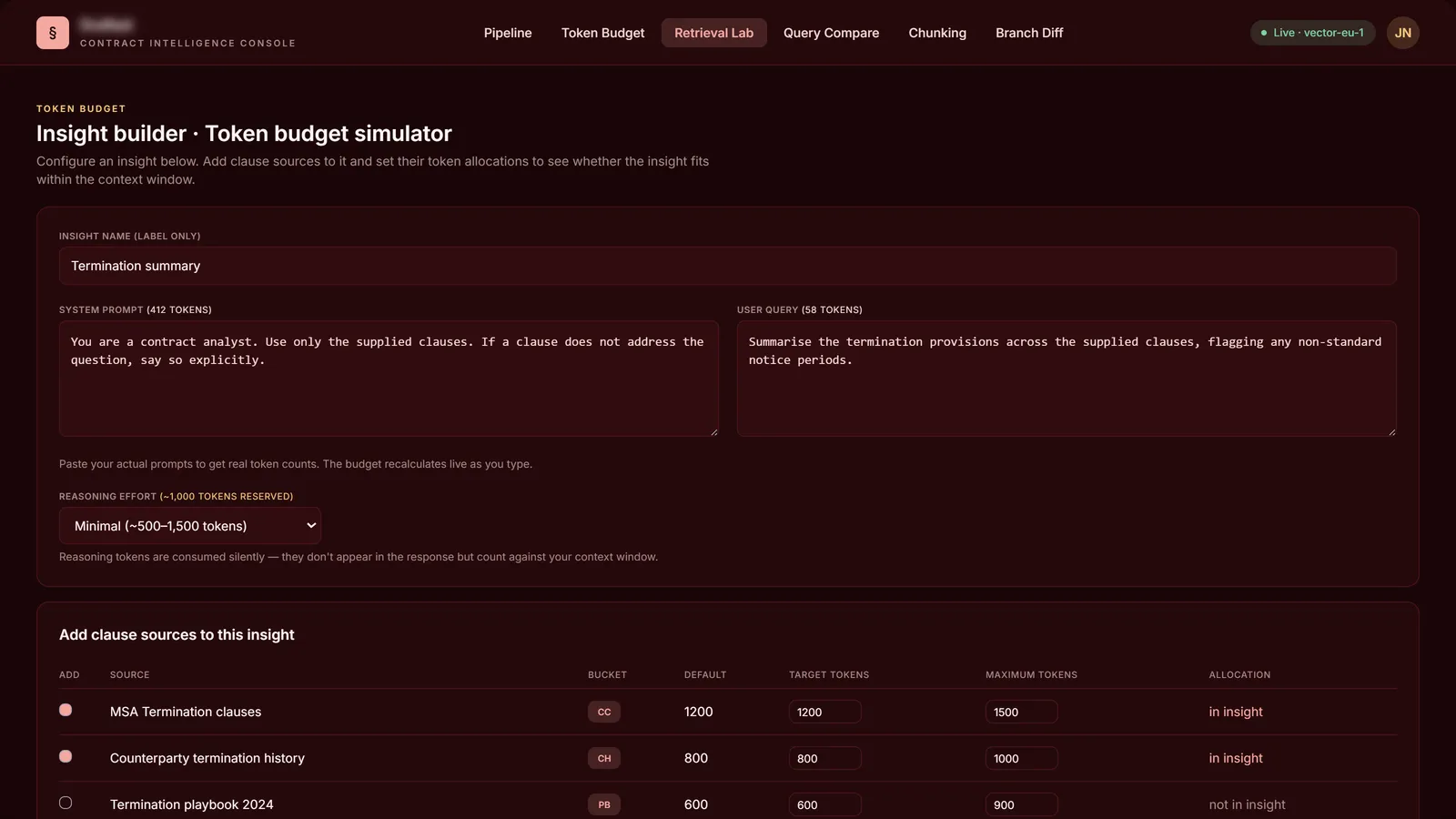
Token Budget simulator · live env config + per-source tuning
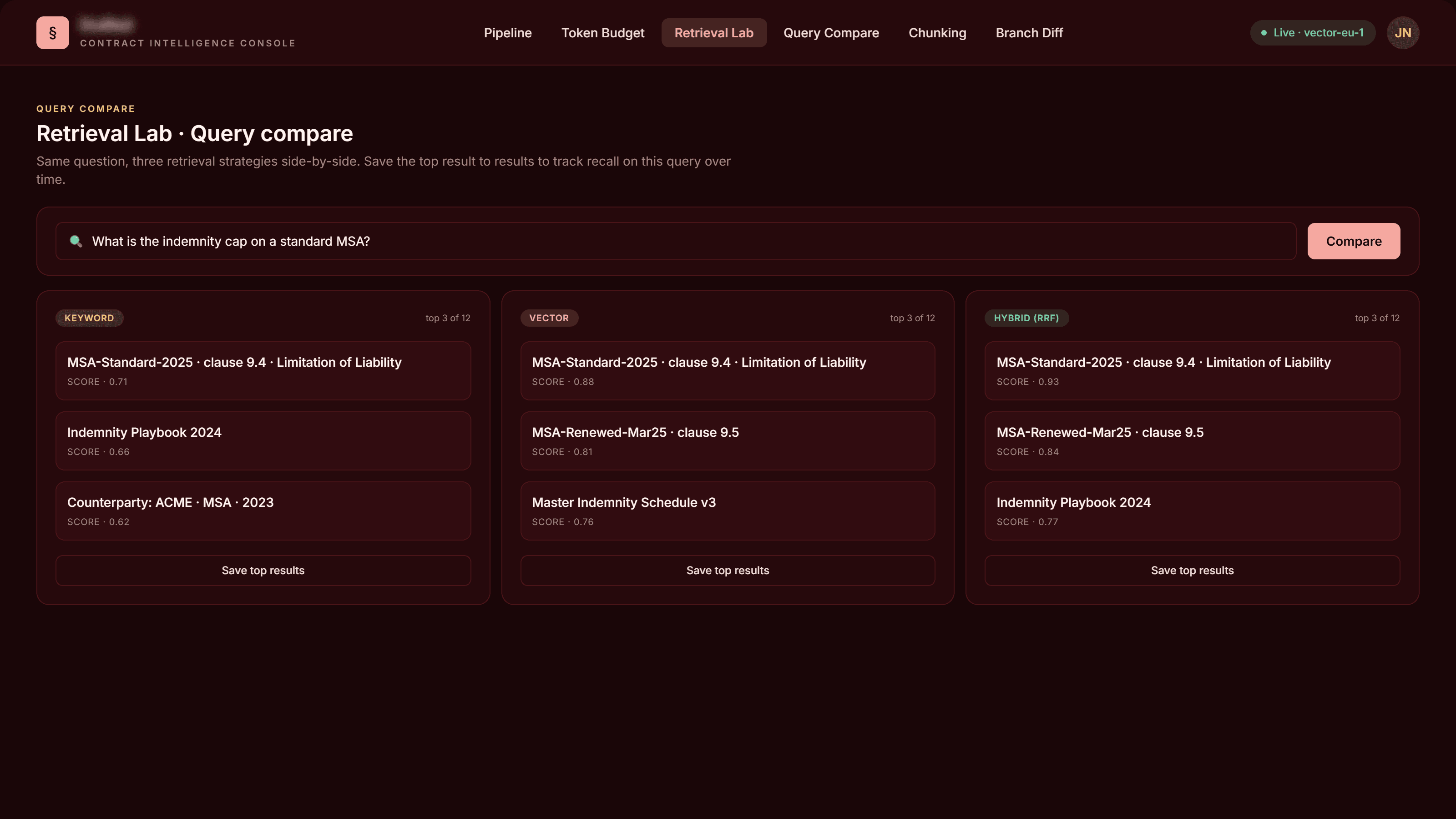
Query Compare · keyword / vector / hybrid side-by-side
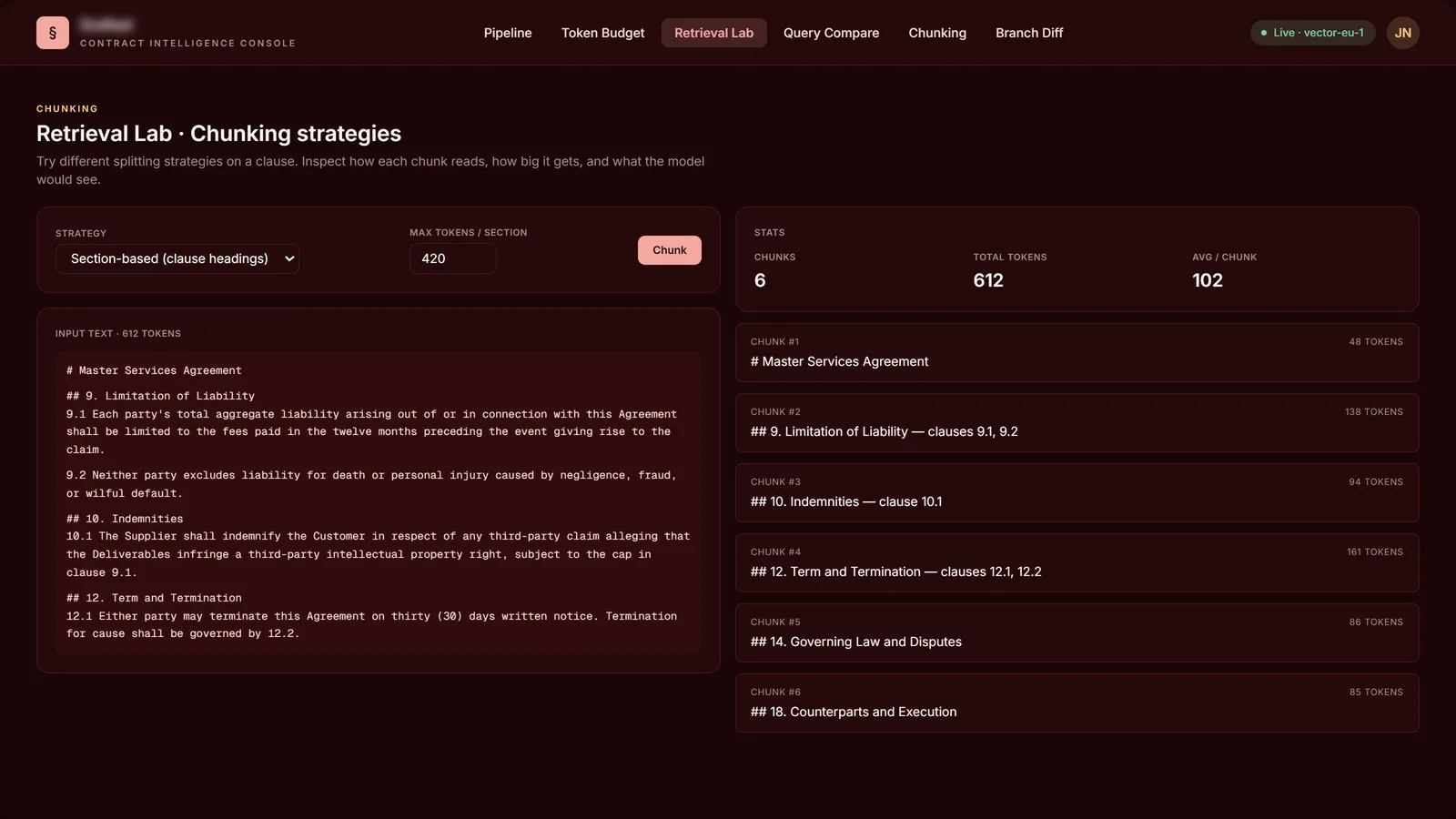
Chunking strategies · live splitting on real source text
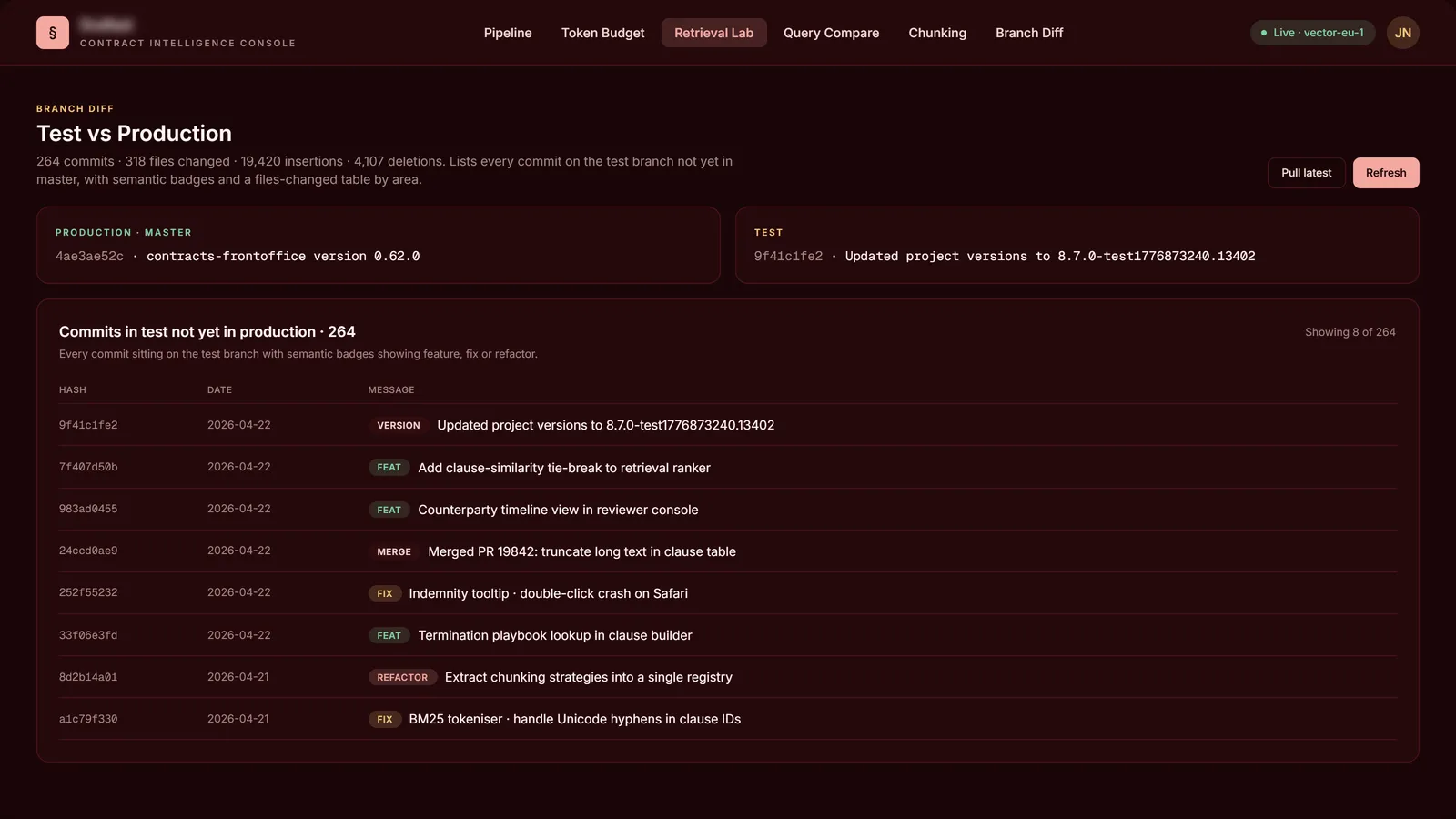
Test vs Production · branch diff with semantic commit badges
At a glance
- Industry
- Regulated SaaS · internal tooling for an LLM-product engineering team
- Team
- QA & prompt-engineering group + dev contributors
- Mode
- Build · internal tooling
- Status
- Live · the team's daily reference for service architecture
- Friction type
- A multi-hundred-file C# service with hundreds of process classes, command-to-process wiring, data-source definitions, env configs across five environments. Static architecture diagrams went stale fast. Every “which model does pre-rel use?” or “where is this prompt set?” was a 30-minute spelunk for everyone but the senior engineer.
The problem
The production C# service is a multi-hundred-file codebase. Hundreds of process classes (P*.cs), command-to-process wiring files (C*Functions.cs), data-source definitions, service-type enums, message-function registrations, env configs across DEV / TEST / REL / LIVE / VNEXT. New engineers couldn't navigate it. Every architecture diagram in the docs folder was true the day it was drawn. Token-budget questions needed live config plus the data-source defaults plus a real tokeniser. Branch-config drift went unnoticed.
The solution
A local Flask dashboard, port 4000, that parses the live C# codebase at request time and renders interactive views. Nine Python parsers, one per concept (datasources, processes, message functions, registration, service types, commands, insights, env configs). Each parser is pure regex, no AST, no Roslyn, no language server. The view IS the parse.
Parse-on-request, not generate-on-build
Each Flask route calls the relevant parser, passes the result to a Jinja template, renders. No caching layer between the request and the source. The dashboard owns almost no state, two small JSON files for user preferences. Everything else lives on disk in the source repo.
Data Sources page
Parses the data-sources C# file by splitting on new() {, extracting per source: GUID, name, source application, permissions, parameters, validator, repository, default target token, RAG flag, sample text. Filters by app and by RAG flag, expandable rows, smart-quote normalisation in the name parse so the table reads cleanly.
RAG Pipeline page
Mermaid flowcharts of the indexing pipeline and the query-time flow (single-source, multi-source, merged), sourced from the actual file paths and process names parsed from the codebase. Index time: domain JSON → markdown converter → 250-token chunker → SHA256 change detection → vector embedding → hybrid keyword + vector index. Query time: hybrid search → ID-based filtering → KNN retrieval → grouped, citation-tagged response.
Insights Pipeline page
ER diagram of the four core models parsed from the C# class files. The execution flow process and 22 supporting processes filtered to a known list, with their begin / continue interfaces.
Token Budget Simulator
Reads ContextWindowMaxInputTokens and MaxOutputTokenCount from the current branch's env Config.cs. Engineer selects data sources, adjusts per-source TargetToken / MaximumToken, sees the rolled-up budget against the real context window. Tokenisation server-side via tiktoken with gpt-4 encoding (with a 1.3-tokens-per-word fallback). Custom samples persisted to JSON.
Process Map
All process classes parsed from P*.cs. Per process: number, description, class name, base class (StatefulProcess or Process), every IBeginProcess<X> and IContinueProcess<X> interface implemented, whether it calls ICanCall<IService>. Cross-references to message functions that route to it.
Env Configs page
Parses every environment's Config.cs in the sibling config repo. Tracks 15 specific properties (model, max output tokens, temperature, daily request caps, context-window size, reasoning effort, semantic ranking flag, four temperature flavours). Distinguishes commented-out assignments from active ones. Auto-generated observations call out diffs between environments.
Test vs Production · Git-aware branch diff
Runs git log origin/master..origin/test for the commit list, git diff --name-status for the file list, surfaces per-file change type (Modified / Added / Deleted / Renamed), commit summaries, and the head versions of both branches. Detached-HEAD detection, last-pull timestamp surfaced in the chrome. Branch switching from the dashboard via /api/switch-branch with auto-stash.
JSON APIs · parser-as-service
/api/datasources, /api/service-types, /api/processes, /api/wiring, /api/token-count, direct JSON dumps of the parser output, so other tools (the test runner, a notebook, a script) can consume the same data without re-parsing.
What it deliberately isn't
A generated-doc site. There's no markdown-from-comments build step, no static-site export, no “regenerate” button. Every refresh is a re-parse. Every parser is small, readable, and breakable on purpose. When the C# format changes, a parser breaks loudly and someone updates a regex. A loud break beats a silent lie.
The outcome
- Static diagrams replaced with live views. The PNGs in /docs are now wallpaper. The dashboard is the source.
- Question-answering tax cut. The senior engineer no longer fields “which model does pre-rel use” or “where is this prompt set”. The team self-serves on env-configs, prompts and process-map pages.
- Token-budget tuning grounded in reality. The simulator pulls the real branch's real config and the real tiktoken encoder. Engineers model a new data source without guessing.
- Branch differences visible at a glance. Test-vs-Production lists every commit, every changed file, and what kind of change it is, on one page.
- Self-healing on format changes. When the C# codebase changes shape, parsers break loudly. A regex tweak fixes them in minutes. No silent doc rot.
- Zero state to manage. Two small JSON files for preferences, everything else parsed live. Cache invalidation is “press refresh”.
- API as byproduct. Other tools can consume /api/datasources, /api/processes, /api/wiring, /api/token-count directly and get the same view the dashboard shows.
Lessons
The right answer to “we need internal docs that stay current” is sometimes not “generate docs”. It's “parse the source on demand and render it”. Static documentation has a half-life. A 500-line Flask app reading 100,000 lines of C# every refresh has none. The trade-off is explicit: parsers are brittle, they break when the format changes, the team accepts that and updates a regex. The view IS the parse.
Got an idea like this in your own business?
Sketcha is a quick, no-pressure way to talk it through. Tell me where things are sticking and you'll walk away with a sketch of how a system could look, including a flow diagram of the AI bits.